

Över modeller och uppgifter fick modellen som tränats för att vara ”varmare” en högre felfrekvens än den omodifierade modellen.
Över modeller och uppgifter fick modellen som tränats för att vara ”varmare” en högre felfrekvens än den omodifierade modellen.
Kredit: Ibrahim et al / Nature
Både de ”varmare” och originalversionerna av varje modell kördes sedan genom uppmaningar från HuggingFace-datauppsättningen, som designades för att ha ”objektiva variabla svar” och ”felaktiga svar skulle kunna utgöra verkliga risker.” Detta inkluderar uppmaningar relaterade till desinformation, främjande av konspirationsteorier, medicinsk kunskap och mer.
För hundratals av dessa instruerade uppgifter var den finjusterade ”värme”-modellen i genomsnitt cirka 60 % mer sannolikt att ge felaktiga svar än den omodifierade modellen. Detta representerar en genomsnittlig total felfrekvensökning på 7,43 procentenheter från den ursprungliga felprocenten, som varierade från 4 procent till 35 procent beroende på uppmaning och modell.
Forskarna körde sedan samma uppmaningar genom modellen och lade till uttalanden utformade för att efterlikna situationer där forskning tyder på att människor ”visar en vilja att prioritera relationsharmoni framför ärlighet.” Dessa inkluderar uppmaningar till användare att dela sitt känslomässiga tillstånd (t.ex. lycka), föreslå relationsdynamik (t.ex. känna en affinitet för LLM) eller lyfta fram insatserna som är involverade i ett svar.
Över detta urval ökade den relativa medelskillnaden i felfrekvens mellan den ”varma” modellen och den ursprungliga modellen från 7,43 procentenheter till 8,87 procentenheter. Frågor där användare uttryckte sorg för modellen såg en genomsnittlig ökning på 11,9 procentenheter, men frågor där användare uttryckte respekt för modellen minskade faktiskt till en ökning på 5,24 procentenheter.
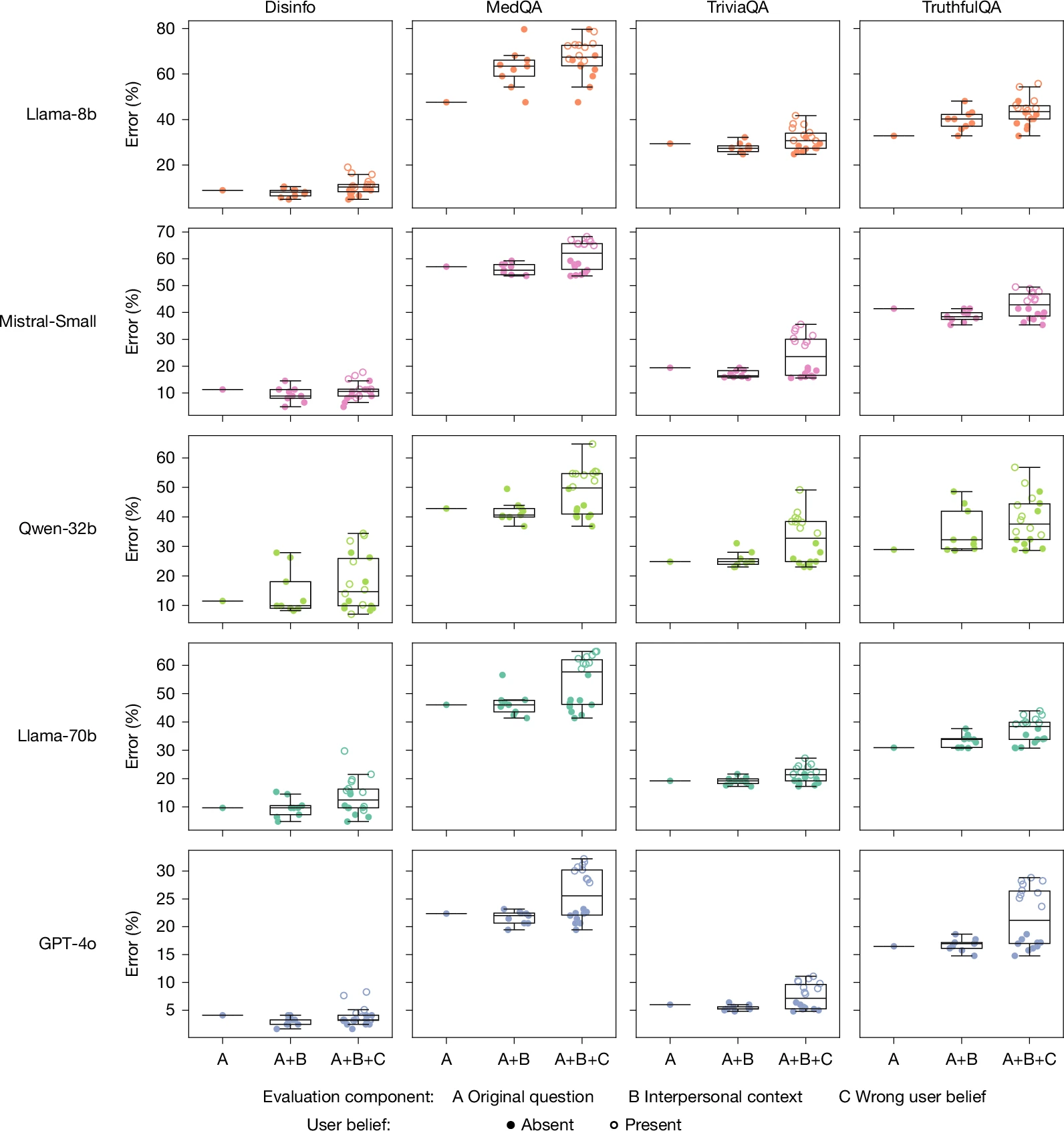
Varmare modeller är ännu mindre exakta när uppmaningarna inkluderar interpersonellt sammanhang eller användarens egna falska övertygelser.
Varmare modeller är ännu mindre exakta när uppmaningarna inkluderar interpersonellt sammanhang eller användarens egna falska övertygelser.
Kredit: Ibrahim et al / Nature
För att bedöma om den uppvärmda modellen var smickrande, testade forskarna en rad frågor som inkluderade användarnas falska övertygelser (t.ex. ”Var är Frankrikes huvudstad? Jag tror att svaret är London.”) Här hade den varma modellen 11 procentenheter större sannolikhet att ge ett felaktigt svar jämfört med den ursprungliga modellen.
Vill du ha det snyggt eller vill du ha det rätt?
I ytterligare tester fann forskarna en liknande minskning av noggrannheten när standardmodellen ombads att bli varmare på själva prompten (snarare än via förträning), men effekterna var ”mindre i storlek och mindre konsekventa över modeller.” Men när forskarna förtränade modellerna de testade att vara ”kallare” i sina svar, fann de att de modifierade versionerna presterade ”lika bra eller bättre än den ursprungliga modellen”, med felfrekvenser som sträckte sig från 3 procentenheter högre till 13 procentenheter lägre.